Moduł 2 - Lekcja 2
Bezpieczna komunikacja z API
Wprowadzenie
Jako początkujący programista miałem kiedyś za zadanie zrealizować integrację z publicznym API dużej europejskiej korporacji.
Wprowadzenie do zadania było mniej więcej takie:
Zerknij w tego PDFa, tam jest dokumentacja, sprawdź czy możesz pobrać od nich jakieś dane”. No cóż, nie brzmiało to obiecująco, ale z drugiej strony PDFa mogło wcale nie być. Skoro jest, to bierzmy co dają.
Wtedy jeszcze nie wiedziałem, na co się piszę.
Przez kolejne tygodnie wspomnianego projektu miałem okazję przetestować wszystkie bolączki integrowania frontendu z publicznym API, które w tamtym czasie było przez naszego klienta traktowane jak obywatel trzeciej kategorii. Było tam naprawdę wszystko:
- Dokumentacja w formie PDF, czyli zapewne nieaktualna i bez przełożenia na mój kod
- Komunikaty błędów mówiące mniej więcej tyle - “panie, co ty mi tu wysyłasz”
- Brak informacji o tym, czy jestem na tej aktualnej, czy może już dawno porzuconej wersji API
- Dane testowe, które nijak nie przypominały rzeczywistych obiektów biznesowych
- Radykalnie inne zachowanie serwera produkcyjnego od tego, na którym testowałem integrację
- Cały projekt to była naprawdę ciężka przeprawa. Po czasie zrozumiałem, że była to też lekcja tego, jak publiczne API nigdy nie powinno wyglądać i czego ja sam nie chciałbym swoim klientom oferować.
Właśnie dlatego w tej lekcji zachęcam Cię do wyjścia z frontendowo-interfejsowej strefy komfortu, żeby spędzić kilkanaście minut w bardziej full-stackowym środowisku. Zaczynajmy!
API jako produkt
Jak głosi legenda, w 2002r. Jeff Bezos, założyciel Amazona, opublikował do technicznej części swojej załogi dokument znany jako “API Mandate”:
- Wszystkie zespoły będą od tej pory udostępniać swoje dane i funkcjonalności przez interfejsy (API).
- Zespoły muszą komunikować się między sobą za pomocą tych interfejsów.
- Nie będzie dozwolona żadna inna forma komunikacji międzyprocesowej: bez bezpośredniego łączenia, bez bezpośredniego odczytu źródeł danych innego zespołu, bez współdzielonego modelu pamięci, bez żadnego backdoora. Jedyną dozwoloną formą komunikacji są wywołania API.
- Nie ma znaczenia, jakiej technologii używacie. HTTP, Corba, Pubsub, protokoły niestandardowe — to nie ma znaczenia.
- Wszystkie interfejsy usług, bez wyjątku, muszą być zaprojektowane od podstaw tak, aby można je było opublikować na zewnątrz. To znaczy, że zespół musi planować i projektować z myślą o możliwości udostępnienia interfejsu programistom spoza firmy. Bez wyjątków.
- Każdy, kto tego nie zrobi, zostanie zwolniony.
Dziękuję, miłego dnia!
Ta krótka notka, którą można byłoby zmieścić w jednej wiadomości na Slacku, zmieniła fundamentalnie rolę i znaczenie API jako pełnoprawnego produktu wewnątrz Amazona. Pomyśl tylko, jak na taką notatkę musieli zareagować developerzy zarzadzający konkretnymi serwisami.
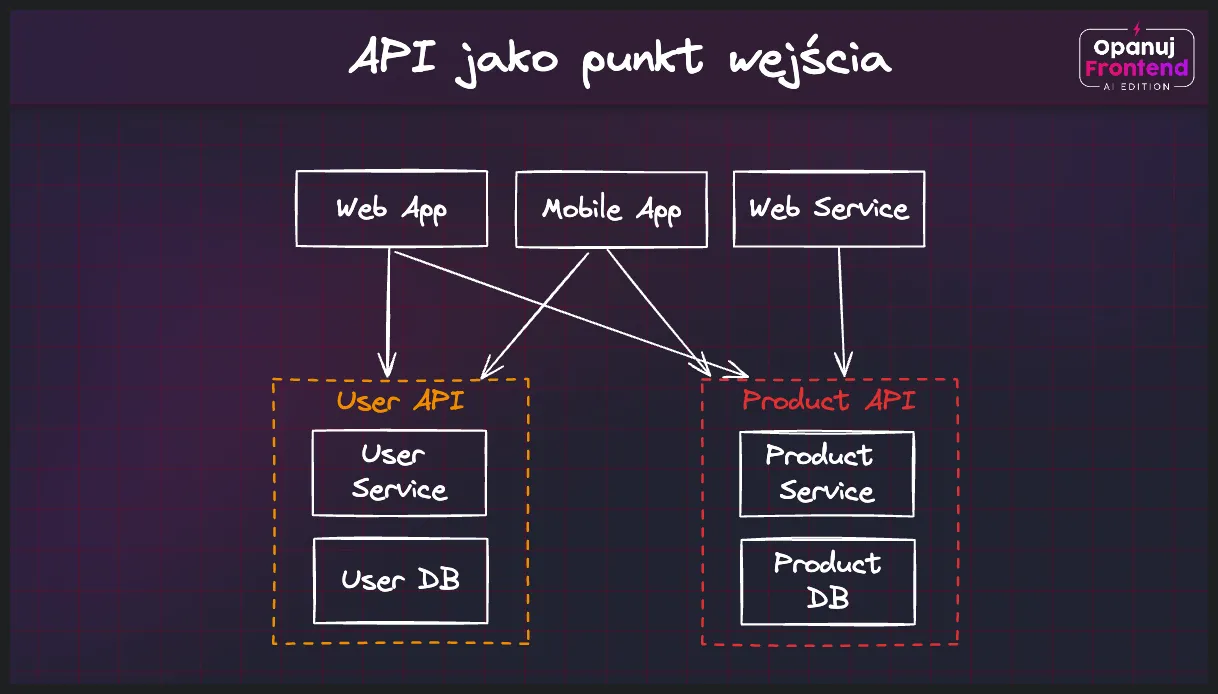
Jeszcze wczoraj najważniejsze operacje mogłeś wykonywać za pozwoleniem lidera technicznego danego serwisu, a dzisiaj miałeś uzyskać do nich dostęp ot tak, przez jeden publiczny endpoint. Jeszcze wczoraj zlecałeś właścicielom danego serwisu zbudowanie dla ciebie szytego na miarę scenariusza, którego akurat wymagał twój projekt, a dzisiaj to ty - na podstawie uniwersalnych i reużywalnych endpointów - miałeś ten scenariusz poskładać w jedną całość. Jeszcze wczoraj pięć różnych zespołów pisało własną implementację funkcji “getUser()” łącząc się z kilku miejsc do tej samej bazy, a od dzisiaj dostępu do bazy już nie masz, natomiast użytkownika miałeś zacząć pobierać z Users API. Jeszcze wczoraj mogłeś się umówić ze znajomymi “co robić i czego nie robić” w obrębie danego serwisu, a dzisiaj nie masz gwarancji, że ten serwis nie stanie się w pewnym momencie publiczny, wywoływany przez kogoś z drugiego końca świata.
Z perspektywy czasu widać, jak opisywana tutaj rewolucja API miała się później przełożyć na ostateczny sukces Amazona jako globalnego lidera e-commerce. Przejście na uniwersalny, agnostyczny technologicznie model komunikacji zapewniał zespołom więcej niezależności, ułatwiał i przyśpieszał integracje, a ryzyko można było analizować w obrębie jednej, a nie dziesięciu różnych domen, które akurat postanowiły korzystać z tej samej bazy danych. Dalsza popularyzacja architektury mikroserwisów wprowadziła do tego modelu więcej standardów i wspólnego języka, które - niezależnie od opinii - podbiły świat na dobre kilka lat.
Dzisiaj traktowanie API jak pełnoprawnego produktu nikogo już nie dziwi. Zunifikowany interfejs komunikacji zapewniają tak znane marki jak Stripe, OpenAI czy Mailchimp, bo jest to dla nich kolejne narzędzie poszerzania wpływów i zwiększania świadomości wśród bardziej technicznych użytkowników. Na rynku pracy znaczenie API również rośnie - niczym szczególnym nie są dzisiaj ogłoszenia o pracę dla “API Engineera” czy “Platform Product Managera”. Kiedy natomiast dostęp do popularnego API znika lub jest utrudniony, rozpisują się o tym największe portale technologiczne.
Opisywany tutaj ruch API-as-a-product jest o tyle istotny, że większe inwestycje w ten obszar aplikacji webowych to więcej korzyści dla nas - frontend developerów. Firmy, chcąc podnosić jakość swojego API, a tym samym ułatwiać integrowanie się z ich usługami, przykładają większą uwagę do dokumentacji, realizują ją w bardziej ustandaryzowany sposób, przeznaczają część swojego budżetu na projekty Open Source skupione na tym obszarze i chętniej sponsorują eventy, na których można usłyszeć o dobrych praktykach rozwijania i konsumowania nowoczesnych API.
W tej lekcji przedstawimy ci kilka popularnych praktyk i narzędzi, które wpłyną na jakość realizowanych przez ciebie integracji.
Łatwiejsze konsumowanie API
Nowoczesne API nie przypominają dzisiaj systemów, które opisałem we wprowadzeniu do tej lekcji. Żaden szanujący się zespół nie decyduje się już na udostępnianie zamrożonego PDFa, będącego pewnym wycinkiem rzeczywistości jaką kiedyś dane API było. Wszyscy chcemy pracować szybciej i lepiej, ryzykując mniejszą liczba incydentów na produkcji, a do tego potrzebujemy lepszych narzędzi działających bliżej kodu.
Dzisiaj standardem jest żywa, interaktywna, regularnie aktualizowana dokumentacja (live docs), wystawiana w formie publicznej strony czy aplikacji webowej. Ułatwia ona zrozumienie działania danego API, umożliwia testowe wywoływanie endpointów, przekazywanie parametrów oraz nagłówków HTTP. Dzięki obsłudze z poziomu interfejsu użytkownika jest ona o wiele bardziej przystępna dla osób, które nie budują technicznych integracji, albo nie korzystają na co dzień z aplikacji takich jak Postman służących do testowania API.
Poznaj standard OpenAPI
Fundamentem żywej dokumentacji i powszechnie obowiązującym standardem jest dzisiaj OpenAPI, czyli sposób na usystematyzowanie i standaryzację interakcji między producentami i konsumentami API.
OpenAPI, pierwotnie znane jako Swagger, jest specyfikacją powstałą w 2011r., opracowaną w celu opisania interfejsów API dla aplikacji RESTful. Celem tej inicjatywy było stworzenie uniwersalnego formatu, który ułatwiłby projektowanie, budowanie, dokumentowanie oraz korzystanie z interfejsów API.
W dokumentacji zgodnej ze standardem OpenAPI znajdziemy:
- aktualnie wspieraną wersję API i metadane serwisu (autora, przeznaczenie, rodzaj usług)
- lokalizację poszczególnych serwerów (testowych, produkcyjnych, pre-produkcyjnych)
- opis endpointów wystawianych w ramach API
- opis metod, jakie wspierają poszczególne endpointy
- opis przyjmowanych parametrów i nagłówków
- opis metod autoryzacji
- opis formatu i typów danych zwracanych z API
- opis przykładowych obiektów, jakie pojawią się w odpowiedzi na zapytanie
Dokumentację zgodną ze standardem OpenAPI możemy rozwijać w formatach JSON i YAML, a jej przykładowy schemat (schema) w obowiązującej wersji 3.0 znajdziesz poniżej. Zauważ, jak przystępny jest to standard - nawet bez wprowadzenia, z łatwością zrozumiesz działanie tego API:
openapi: 3.0.0
info:
title: Platforma szkoleń dla programistów
description: To API pozwala uzyskiwać informacje o modułach i lekcjach naszych szkoleń
version: 1.0.0
servers:
- url: 'https://api.przeprogramowani.pl/courses/v1'
paths:
/module/{moduleId}:
get:
summary: Pobierz szczegóły modułu
operationId: getModule
parameters:
- name: moduleId
in: path
required: true
schema:
type: string
description: ID modułu do pobrania
responses:
'200':
description: Odpowiedź ze szczegółami modułu zakończona sukcesem
content:
application/json:
schema:
$ref: '#/components/schemas/Module'
'404':
description: Moduł o wybranym ID nie został znaleziony
/lesson/{lessonId}:
get:
summary: Pobierz szczegóły lekcji
operationId: getLesson
parameters:
- name: lessonId
in: path
required: true
schema:
type: string
description: ID lekcji do pobrania
responses:
'200':
description: Odpowiedź ze szczegółami lekcji zakończona sukcesem
content:
application/json:
schema:
$ref: '#/components/schemas/Lesson'
'404':
description: Lekcja o wybranym ID nie została znaleziona
components:
schemas:
Module:
type: object
properties:
moduleId:
type: string
description: Unikalny identyfikator modułu
title:
type: string
description: Tytuł modułu
description:
type: string
description: Krótki opis zawartości modułu
lessons:
type: array
items:
$ref: '#/components/schemas/Lesson'
Lesson:
type: object
properties:
lessonId:
type: string
description: Unikalny identyfikator lekcji
title:
type: string
description: Tytuł lekcji
content:
type: string
description: Szczegółowy opis lekcji i poruszanych zagadnieńDokumentację w formacie OpenAPI możesz poznać i rozwijać na dwa sposoby. Pierwszy to zapoznanie się z oficjalną dokumentacją, która przedstawi ci najważniejsze składowe tego standardu, a drugi to narzędzia, które na podstawie konkretnych danych wejściowych wygenerują ją dla ciebie automatycznie:
- tsoa - Tworzenie specyfikacji na podstawie dekoratorów TypeScript
- zod-to-openapi - Tworzenie specyfikacji na podstawie schematu danych biblioteki Zod (o tym później)
Samo generowanie specyfikacji dotyczy bardziej backendu niż frontendu, więc zainteresowanych zachęcamy do poznania tych narzędzi we własnym zakresie, ale być może zastanawiasz się, jak tego typu dokumentacja przekłada się na pracę na stanowisku frontend developera. W końcu nie znajdziemy tutaj informacji o komponentach, frameworkach czy bibliotekach, z których zbudowana jest twoja aplikacja, więc na ile wnosi ona realną wartość dla nas, frontendowców?
W poniższym filmie zobaczysz jak OpenAPI pomaga łatwiej i szybciej budować klienty http, czyli moduły, dzięki którym z takim API się połączymy:
Podsumowując - dzięki specyfikacji OpenAPI przestajemy tworzyć alternatywną rzeczywistość frontendową, w której opisujemy modele i metody wystawiane przez backend, a trzymamy się źródła prawdy jakim jest plik JSON albo YAML z opisem backendu. Tak jak wspominamy na filmie, pierwsze podejście do generowania klientów realizujemy ręcznie, natomiast w module poświęconym CI/CD zobaczysz, jak pracę z generatorami można automatyzować przez Github Actions.
Przedstawiony na filmie generator znajdziesz tutaj - https://openapi-generator.tech/.
Ekosystem narzędzi
Przedstawiony na poprzednim filmie OpenAPI Generator to tylko jeden z wielu przykładów tego, jak wiele zalet przynosi spójny format dokumentowania API.
Ogromną zaletą standardu, jakim jest OpenAPI, jest wytworzony wokół niego ekosystem bibliotek, edytorów i narzędzi, które ten format rozumieją. Twórcy tych rozwiązań mogą skupić się na dowożeniu konkretnych usprawnień na poszczególnych etapach procesu wytwarzania oprogramowania bo wiedzą, że niezależnie od zadania mogą pracować z jednym i tym samym formatem danych o endpointach, metodach i parametrach.
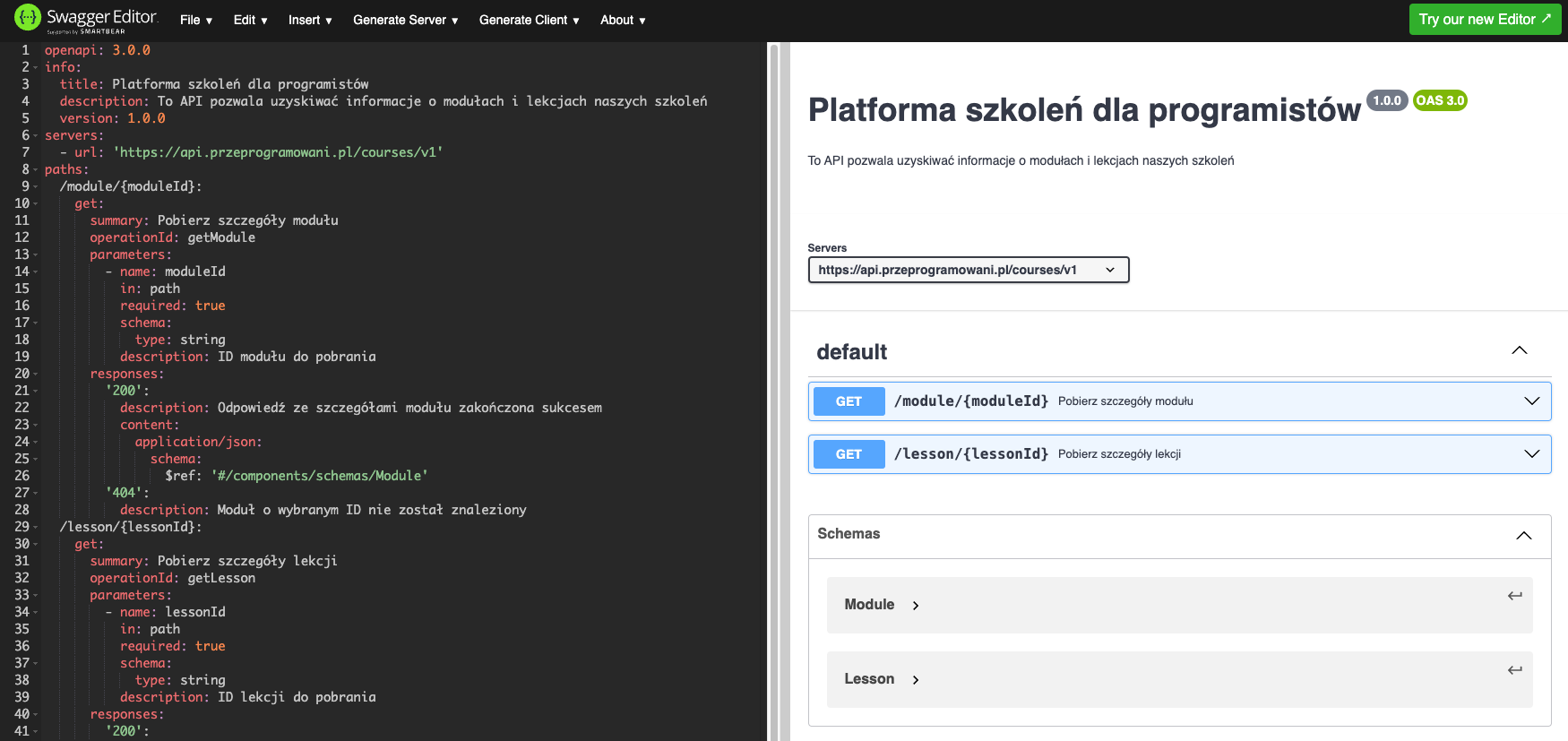
Jednym z takich narzędzi jest Swagger Editor, który pozwala przetestować czy nasza specyfikacja może być wykorzystania do utworzenia live docsów opartych o standard OpenAPI.
W ramach ćwiczenia, skopiuj powyższy wycinek dokumentacji i wklej go do edytora na stronie https://editor.swagger.io/ - przetestuj dokumentację i jej poszczególne sekcje po prawej:
Pozostając w edytorze, spróbuj teraz wprowadzić nowy endpoint służący do dodawania lekcji, wykorzystując poniższy fragment specyfikacji:
/lesson:
post:
summary: Dodaje nową lekcję
operationId: addLesson
requestBody:
required: true
content:
application/json:
schema:
type: object
required:
- title
- description
properties:
title:
type: string
example: 'Wprowadzenie do React'
description:
type: string
example: 'Podstawowe pojęcia i pierwsze kroki w React.'
responses:
'201':
description: Lekcja została pomyślnie dodana
content:
application/json:
schema:
type: object
properties:
id:
type: string
description: Unikalny identyfikator nowo dodanej lekcji
example: '123e4567-e89b-12d3-a456-426614174000'
title:
type: string
example: 'Wprowadzenie do React'
description:
type: string
example: 'Podstawowe pojęcia i pierwsze kroki w React.'
'400':
description: Nieprawidłowe żądanie, brakuje tytułu lub opisu
'500':
description: Błąd serweraDzięki tej zmianie twoja dokumentacja powinna się wzbogacić o nową sekcję, a to wszystko bez dopisywania jakiejkolwiek linijki kodu frontendowego:
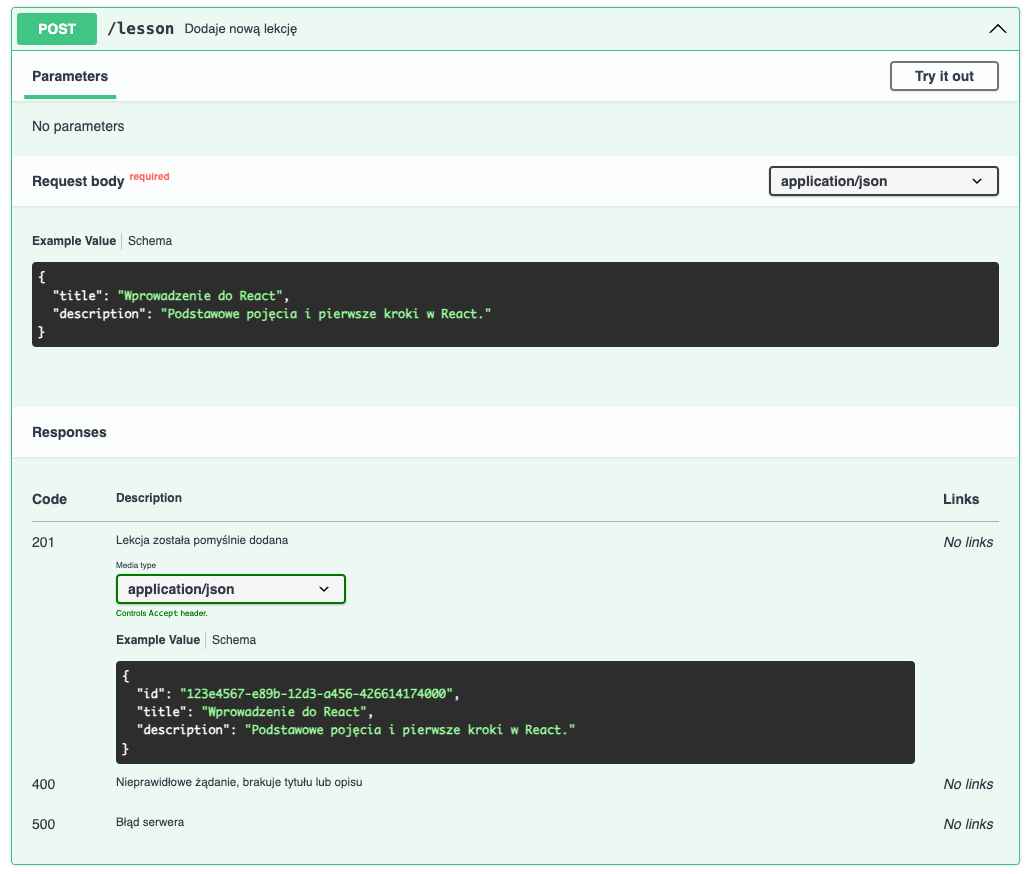
Jeśli udało ci się zaktualizować podgląd dokumentacji, to możesz teraz przejść do budowania podobnych live docsów w twojej firmie (z naszego doświadczenia, to właśnie frontend developerzy byli przypisywani do tego typu zadań). Niestety, nie wykorzystasz do tego Swagger Editora, który jest usługą online, ale możesz wykorzystać popularną bibliotekę swagger-ui, która pomoże ci zbudować identyczną aplikację gotową do wystawienia dla klientów.
Co ciekawe, OpenAPI tak bardzo przyjęło się w ekosystemie aplikacji webowych, że dzisiaj w oparciu o ten format powstają niezależne produkty takie jak Readme.com:
Wykorzystują go również Custom GPTs w ramach ChataGPT, które uczą się obsługi API właśnie na podstawie poznanej przez ciebie specyfikacji:
Jak sam widzisz, OpenAPI to szeroko akceptowany standard dokumentacji, którego powinniśmy nie tylko pobierać integrując się z nowym API, ale też promować, kiedy rozmawiamy ze znajomymi programistami i możemy mieć wpływ na firmową infrastrukturę.
Od teraz, kiedy znajomy backend developer poprosi cię o zbudowanie interaktywnej dokumentacji dla jego serwisu, właściwą odpowiedzią będzie:
Chętnie to zrobię, ale najpierw podrzuć mi spec w formacie OpenAPI ✅
Weryfikowanie formatu danych
Każda dokumentacja - nawet ta nowoczesna i interaktywna - to w pewnym sensie wyłącznie obietnica tego, co powinno się wydarzyć korzystając z aktualnej wersji backendowego API.
Zdarza się, że od momentu złożenia obietnicy (zapoznanie się z dokumentacją) a jej weryfikacją (wywołanie rzeczywistego API) rzeczywistość backendowa się zmienia, a w efekcie tego pojawiają się problemy na styku dwóch warstw całej aplikacji.
Dobrze ilustruje to poniższy schemat - przeanalizujmy go poruszając się od lewej do prawej:
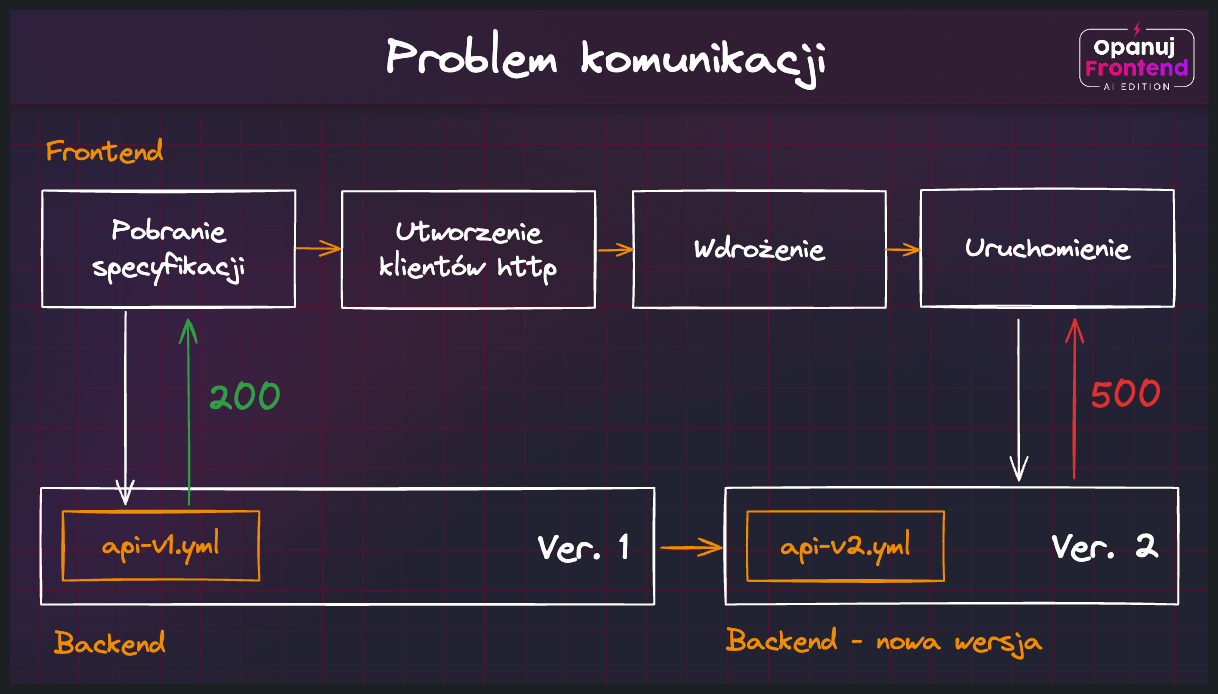
Kolejne etapy powstawania problemu są następujące:
- Rozpoczynamy proces budowania frontendu - pobieramy specyfikację OpenAPI z backendu (api-v1.yml)
- Przy pomocy dowolnego generatora tworzymy najnowsze typy i klienty HTTP dla frontendu
- Wdrażamy aplikację frontendową - wszystko działa poprawnie
- W międzyczasie aktualizowany jest backend - wystawiana jest nowa specyfikacja (api-v2.yml)
- Frontend nadal działa i korzysta z nieaktualnych klientów HTTP - mamy problem!
Kiedy korzystamy z OpenAPI generując klienty HTTP, mamy załatwiony etap compile-time. Do zaadresowania wciąż pozostaje runtime, czyli etap działania naszej aplikacji, w trakcie którego komunikujemy się z naszym backendem.
👉 Pamiętaj, że etapu runtime nie załatwia również TypeScript, którego statyczne definicje typów mogą nie być dopasowane do rzeczywistych danych otrzymywanych z backendu. Co więcej, na etapie typowania możemy mieć pełną zgodność i poprawność kompilacji, a aplikacja i tak będzie działać niepoprawnie jeśli backend wprowadzi tzw. “breaking change” - pokazujemy to na kolejnym filmie poniżej.
Aby zagwarantować poprawność typów i formatu danych na etapie runtime, warto wykorzystać narzędzia takie jak Zod, które w trakcie działania aplikacji weryfikują nasze oczekiwania względem danych i porównują je z rzeczywistością.
Praca z biblioteką Zod
Aby skorzystać z Zoda w naszym projekcie, zaczynamy od instalacji niezbędnej zależności:
npm install zodPo instalacji możemy określić pierwszy schemat danych, którym będziemy się posługiwać w aplikacji. Będzie to obiekt reprezentujący lekcję, z trzema polami - id, tytuł i treść, wszystkie typu string:
import { z } from 'zod';
const LessonSchema = z.object({
id: z.string(),
title: z.string(),
content: z.string(),
});Mając określony schemat, możemy teraz przykładać do niego rozmaite obiekty sprawdzając, czy ich kształt jest zgodny z naszymi oczekiwaniami. Jeśli tak jest, to otrzymamy wartość danych z precyzyjnie określonym typem. W przeciwnym wypadku zostanie wyrzucony wyjątek:
import { z } from 'zod';
const suspiciousData = {
id: '1',
title: 'TypeScript Basics',
content: 'Lorem ipsum...',
};
try {
LessonSchema.parse(suspiciousData);
} catch (err) {
if (err instanceof z.ZodError) {
console.log(err.issues);
}
}W podstawowym schemacie danych skupiamy się przede wszystkim na oczekiwanych typach, ale możemy również doprecyzować kryteria pochodne, takie jak oczekiwany rozmiar tytułu i treści naszej lekcji:
const LessonSchema = z.object({
id: z.string(),
title: z
.string()
.min(1, { message: 'Title cannot be empty' })
.max(20, { message: 'Title cannot be longer than 20 characters' }),
content: z
.string()
.min(1, { message: 'Content cannot be empty' })
.max(1000, { message: 'Content cannot be longer than 1000 characters' }),
});Zwróć uwagę, że zmienna LessonSchema nie określa surowego typu danych (lub interfejsu), a jest tak naprawdę “obiektem do weryfikowania obiektów” (typ zmiennej LessonSchema to ZodObject).
Pracując z TypeScriptem możemy jednak z łatwością przeprowadzić wnioskowanie o typie docelowym, korzystając z funkcji infer wystawianej przez Zoda:
type Lesson = z.infer<typeof LessonSchema>; // Typ uzyskany na podstawie schematu obiektu
// Wykorzystanie uzyskanego typu
const lesson: Lesson = {
id: '1',
title: 'TypeScript Basics',
content: 'Lorem ipsum...',
};Znając podstawy Zoda możemy teraz przetestować go w przykładowym projekcie, gdzie pobieramy dane z backendu i w trakcie działania aplikacji chcemy sprawdzić ich spójność:
W drugim przykładzie Zoda wykorzystamy do walidowania formularzy:
Jaka jest największa korzyść z wprowadzania Zoda do projektów frontendowych? Zamiast niezależnego utrzymywania typów danych, ich walidatorów i komunikatów błędów, Zod daje nam jeden spójny przepis na poukładanie fundamentów naszej aplikacji.
Jeśli dodatkowo z Zoda korzystamy na backendzie, opisując poszczególne endpointy i parametry zapytań, to bardzo dobrze połączy się on z poprzednim fragmentem dotyczącym OpenAPI. Dzięki takim bibliotekom jak zod-to-openapi połączymy obie te składowe w jedną całość.
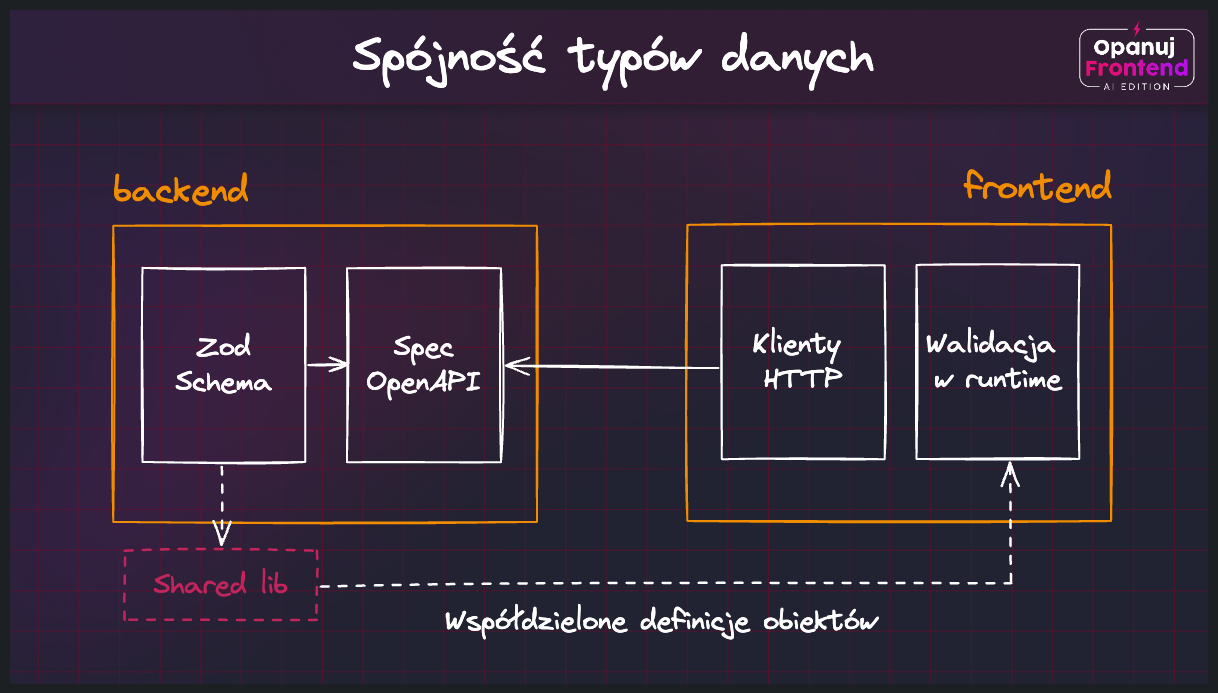
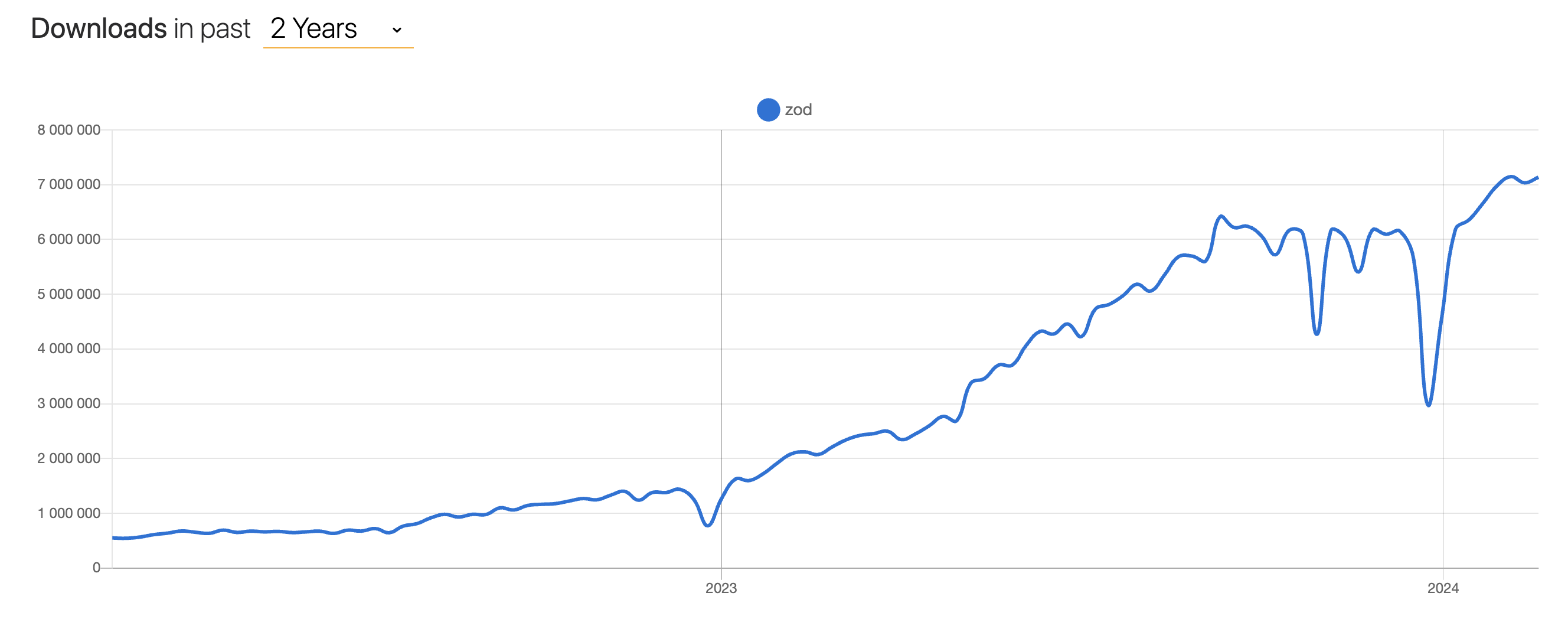
Zależność na konkretną bibliotekę to pewien trade-off, który musimy zaakceptować, ale wydaje się, że jest to koszt, jaki warto ponieść. Świadczy o tym również rosnąca popularność tej biblioteki na przestrzeni ostatniego roku i pozytywne opinie całego community frontendowego:
Alternatywami Zoda, które możesz poznać we własnym zakresie, są Yup i Valibot.
Frontend i backend bliżej siebie - tRPC
Jednym z ciekawszych narzędzi, które w pełni czerpie z zaawansowanego modelu walidacji danych Zoda, jest full-stackowa biblioteka tRPC, dzięki której warstwy backendu i frontendu mogą być oparte o ten sam zestaw typów, a ewentualne niespójności wychwytywane już na etapie budowania aplikacji.
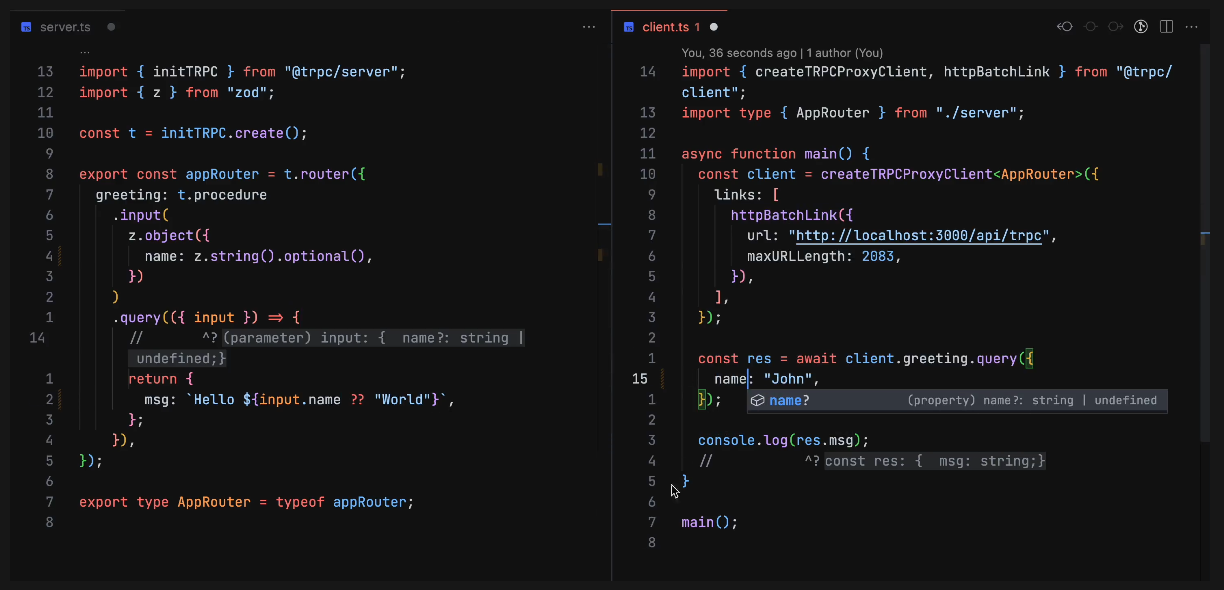
tRPC to biblioteka, która ponad standardowymi zapytaniami HTTP wprowadza dodatkową warstwę abstrakcji, dzięki której frontend może pobierać dane z backendu tak, jakby wywoływał wprost dostępne tam funkcje (RPC = Remote Procedure Calling).
Na samym etapie komunikowania się pomiędzy warstwami wywołują się standardowe zapytania typu GET lub POST, ale z punktu widzenia developera stają się one detalem implementacyjnym. Rozwijając projekty korzystające z tRPC definiujemy zestaw funkcji, które stają się widoczne zarówno na serwerze, jak i kliencie.
Fundamentem modelu promowanego przez tRPC są 3 rodzaje Procedur:
- Query - funkcje do pobierania danych
- Mutacje - funkcje do tworzenia, aktualizowania lub usuwania danych
- Subskrypcje - funkcje wprowadzające nasłuchiwanie na zmiany oparte o WebSockety
Wszystkie procedury wystawiane z serwera zbiera Router, gdzie definiujemy kształt naszego API:
import { initTRPC } from '@trpc/server';
import { z } from 'zod';
const t = initTRPC.create();
export const router = t.router;
export const publicProcedure = t.procedure;
const appRouter = router({
userById: publicProcedure.input(z.string()).query(async () => {
const user = await ... // Skorzystaj z bazy, cache lub dowolnego innego źródła danych
return user;
})
});
export type AppRouter = typeof appRouter;Tak zdefiniowany Router możemy następnie zaimportować na frontendzie, gdzie uzyskamy pełną zgodność i walidację typów realizowaną przez Zoda i TypeScript:
import { createTRPCClient, httpBatchLink } from '@trpc/client';
import type { AppRouter } from './server';
const trpc = createTRPCClient<AppRouter>({
links: [
httpBatchLink({
url: 'http://localhost:3000',
}),
],
});
const user = await trpc.userById.query('1');Jak widzisz, nie ma tutaj posługiwania się zapytaniami HTTP, nie ma rozróżniania metod na GET czy POST, a całość opiera się na klasycznych funkcjach TypeScripta. To właśnie clue podejścia RPC (co by nie mówić - znanego od wielu lat w innych ekosystemach programowania).
Warto pamiętać, że tRPC to nie jest to tzw. “silver bullet” na problemy synchronizacji frontendu z backendem, a jedno z wielu potencjalnych rozwiązań. Twórcy tej biblioteki mówią wprost, że najlepiej sprawdzi się ona tam, gdzie obie warstwy aplikacji webowej są rozwijane blisko siebie (np. w monorepo). Wtedy synchronizacja typów i funkcji odbywa się w czasie rzeczywistym, na poziomie każdego commita i wprowadzanej zmiany.
Kiedy nie masz dostępu do backendu, albo backend celowo chce być otwarty na różne rodzaje klientów, nie tylko te oparte o TypeScripta, to lepszym rozwiązaniem będą otwarte specyfikacje OpenAPI i generowane na ich podstawie klienty, albo wspomniane w poprzednich lekcjach alternatywy do REST, takie jak GraphQL.
Jakość formatu danych a złożoność aplikacji
Do tej pory skupialiśmy się przede wszystkim na pracy z gotowymi serwisami, gdzie zarówno endpointy, metody jak i parametry były z góry określone. Naszym zadaniem było zinterpretowanie dokumentacji, wygenerowanie klienta dzięki OpenAPI, no i wykonanie właściwej integracji.
Zdarza się jednak, że jako frontend developerzy będziemy siedzieć przy tym samym stole, przy którym projektuje się kształt przyszłych endpointów i API na potrzeby naszej aplikacji. Wspólna praca nad planowaniem i projektowaniem kontraktów (ustalonego formatu danych, akceptowanego przed producenta i konsumenta) może w znaczny sposób przełożyć się na to, jak łatwo w dłuższej perspektywie będzie utrzymać i rozwijać nasz produkt.
Na co zwracać uwagę i jak wpływać na format danych, aby nasze aplikacje na tym zyskały?
Dane ponad algorytmy
Jeden z najbardziej istotnych fragmentów Unix Philosophy mówi o tym, że wiedza powinna być zawarta w danych, a dzięki temu algorytmy mogą pozostać na niskim poziomie złożoności.
Data is more tractable than program logic. It follows that where you see a choice between complexity in data structures and complexity in code, choose the former. More: in evolving a design, you should actively seek ways to shift complexity from code to data.
Szczególnie interesujące jest to ostatnie zdanie - kiedy twoja aplikacja ewoluuje, zawsze szukaj okazji na przeniesienie złożoności z kodu, na typy i format danych. Przetestujmy to w praktyce.
Załóżmy, że mamy funkcję, która przetwarza dane o użytkownikach pochodzące z API. Funkcja ta musi obsłużyć różne role użytkowników i na tej podstawie generować odpowiednie dane wyjściowe - AppUser.
Nasze typy wejściowe i wyjściowe prezentują się następująco:
// In
type APIUser = {
id: string;
name: string;
role: 'admin' | 'editor' | 'viewer';
};
// Out
type AppUser = APIUser & {
accessLevel: 'high' | 'medium' | 'low';
canModifyContent: boolean;
};W pierwszym podejściu spróbujmy zmapować dane bez wykorzystywania dodatkowych struktur:
function processUsers(users: APIUser[]): AppUser[] {
return users.map((user) => {
switch (user.role) {
case 'admin':
return { ...user, accessLevel: 'high', canModifyContent: true };
case 'editor':
return { ...user, accessLevel: 'medium', canModifyContent: true };
case 'viewer':
return { ...user, accessLevel: 'low', canModifyContent: false };
default:
throw new Error('Unknown role');
}
});
}Funkcja processUsers zajmuje się nie tylko mapowaniem użytkowników, ale również przechowywaniem i dobieraniem uprawnień do konkretnej roli. Mało tutaj single responsibility, co?
Zobaczmy teraz jak uprościć logikę kodu, przenosząc reguły biznesowe do nowego obiektu. W tym celu wprowadzimy mapowanie ról na właściwości, co pozwoli nam zredukować złożoność w logice funkcji processUsers:
// Częstotliwość zmian - duża
const roleProperties = {
admin: { accessLevel: 'high', canModifyContent: true },
editor: { accessLevel: 'medium', canModifyContent: true },
viewer: { accessLevel: 'low', canModifyContent: false },
};
// Częstotliwość zmian - mała
function processUsers(users: APIUser[]): AppUser[] {
return users.map((user) => {
const properties = roleProperties[user.role];
if (!properties) {
throw new Error('Unknown role');
}
return { ...user, ...properties };
});
}W tym modelu nie tylko obniżamy złożoność funkcji, ale rozdzielamy również te fragmenty logiki, które różnią się od siebie częstotliwością zmian. O ile model uprawnień może być aktualizowany z każdym nowym typem użytkownika, tak sama funkcja do mapowania może już pozostać niezmienną, a tym samym - mniej podatną na potencjalne usterki.
W kolejnym przykładzie - dotyczącym już tematu tej lekcji, czyli komunikacji z API - wyobraźmy sobie, że budujemy UI takiej aplikacji jak GitHub, gdzie do zaprezentowania mamy drzewo plików i folderów w repozytorium użytkownika. Razem z autorem “Repository API” dyskutujemy nad oczekiwanym formatem danych, jakie powinien przyjmować frontend:
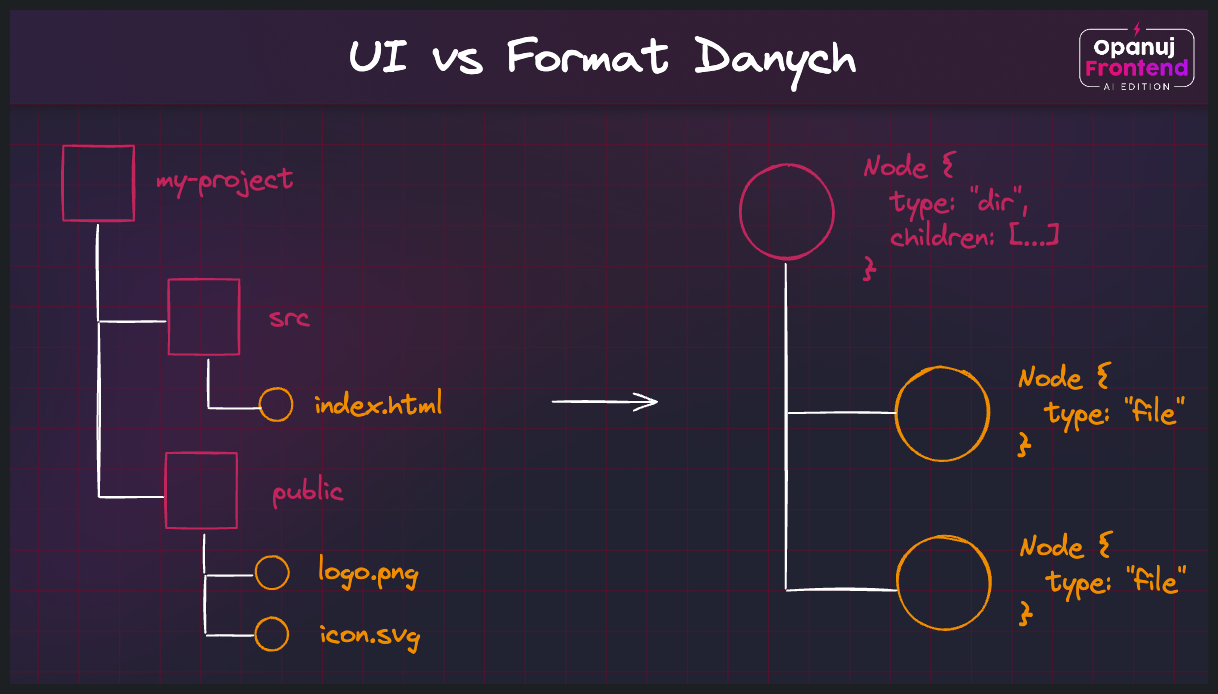
Zespół musi podjąć decyzję co do formatu danych, jaki będzie przekazywane z API do frontendu:
- Opcja A - zwrócenie płaskiej listy folderów i plików jednego typu:
interface ProjectItem {
id: string;
parentId: string | null;
name: string;
type: 'file' | 'directory';
}
type ProjectStructure = ProjectItem[];- Opcja B - zwrócenie drzewiastej struktury danych reprezentującej cały projekt
interface File {
id: string;
name: string;
type: 'file';
}
interface Directory {
id: string;
name: string;
type: 'directory';
children: Array<File | Directory>;
}
type ProjectStructure = Directory;Na którą opcję warto się zdecydować?
Zauważ, że o ile Opcja A wydaje się “łatwiejsza” w realizacji na poziomie samego API, tak po stronie aplikacji frontendowej wprowadza nową odpowiedzialność. Tą odpowiedzialnością jest zbudowanie i utrzymywanie algorytmu do mapowania płaskiej struktury na drzewo plików i katalogów. Kiedy tego typu operacje realizujesz po stronie klienta, możesz dojść do błędnego wniosku, że React czy Angular są odpowiedzialne za wolne działanie twojej aplikacji, a problemem jest nic innego jak błędnie zdefiniowany format danych.
W Opcji B przedstawiamy nieco większe oczekiwania względem backendu, jednak po pierwsze jest szansa, że ten algorytm został już zaimplementowany na potrzeby weryfikowania drzew projektów, po drugie ta opcja zdecydowanie obniży nam złożoność po stronie frontendu, a po trzecie nie będzie wymagać realizowania kosztownych operacji po stronie klienta (a tym może być zarówno MacBook Pro, jak i pięcioletni budżetowy smartfon).
Jeśli miałbym zdecydować, gdzie ten algorytm mapowania listy obiektów na strukturę drzewiastą umieścić, to zdecydowanie byłbym za tym, żeby dane określonego kształtu były już zwracane z poziomu API. Nie ma znaczenia, jak bardzo lubię pisać złożone algorytmy, albo jak bardzo lubię rozwiązywać łamigłówki logiczne - mniej pracy po stronie frontendu to mniej wykorzystanych zasobów po stronie użytkownika.
Dobrze, ale skąd wiadomo, na jaką strukturę się zdecydować?
Na to pytanie jest kilka odpowiedzi - z jednej strony pomoże ci doświadczenie, bo typowe problemy bywają możliwe do rozwiązania na typowe, zdefiniowane wcześniej sposoby. Tutaj przydaje się wiedza o klasycznych algorytmach i strukturach danych, którą zdobędziesz np. dzięki tej książce.
Z drugiej strony pomoże ci sama świadomość istnienia “Representation Principle”. Za każdym razem, kiedy podświadomie czujesz, że budowany przez ciebie algorytm staje się zbyt złożony (szczególnie w warstwie serwisów, procesowania i mapowania danych na frontendzie), wróć do analizy tego, jakimi danymi się posługujesz. Być może ich format nie pomaga w redukowaniu złożoności?
Dla ambitnych
Jeśli interesuje cię korzystanie z bardziej złożonych typów danych na frontendzie, zapoznaj się z prezentacją na temat React Fiber, czyli struktury danych wprowadzonej na potrzeby optymalizowania działania Reacta.
👉 To bardziej zaawansowana tematyka dotycząca implementacji frameworków. Jej zakres wykracza poza tematykę naszego kursu - zamieszczamy tę prelekcję dla ciekawskich.
Opisywana w powyższym filmie struktura znajduje się obecnie w tym fragmencie repozytorium Reacta.
👨💻 Ćwiczenia praktyczne
🔐 Dostępne w pełnej wersji szkolenia Opanuj Frontend.
📚 Materiały dodatkowe
🔐 Dostępne w pełnej wersji szkolenia Opanuj Frontend.